
文章代码源于这里:https://www.zhuxianfei.com/python/47350.html。
Artificial Intelligence / Reverse Engineering / Internet of Things / Full Stack Developer
文章代码源于这里:https://www.zhuxianfei.com/python/47350.html。
网上搜一下,读取cookie的基本都是这份代码。我也忘了是从那里抄来的了,这里贴一下 ,对于最新的chrome需要修改下路径:
# chrome 96 版本以下 # filename = os.path.join(os.environ['USERPROFILE'], r'AppData\Local\Google\Chrome\User Data\default\Cookies') # chrome96 版本以上 # filename = os.path.join(os.environ['USERPROFILE'], r'AppData\Local\Google\Chrome\User Data\default\Network\Cookies')

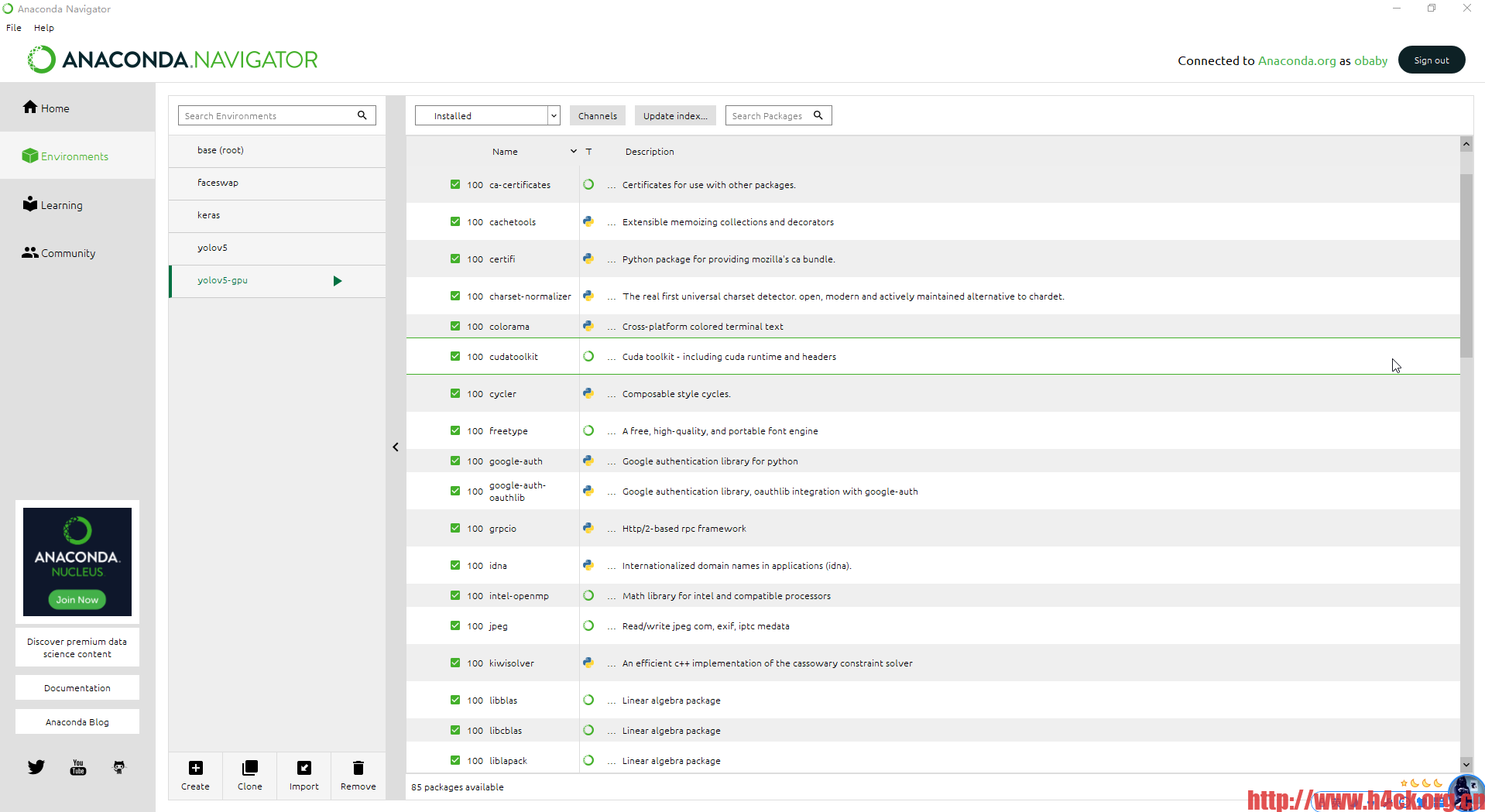
xiurenji.exe 可执行文件名称 帮助: -h 显示帮助说明 必选参数: -a 整站爬取 -q 搜索爬取,针对关键字搜索之后对于搜索结果页进行爬取 可选参数: -p 指定下载目录,默认下载路径为当前exe所在目录下的images文件夹 -s 指定服务器地址,例如:http://www.xiurenji.vip url不要带最后的/
更新日志:
增加-s 参数支持: -s 指定服务器地址,例如:http://www.xiurenji.vip url不要带最后的/

接引前文《Windows 10 yolov5 GPU环境》,配置完成之后,一度因为虚拟内存没什么太大用处。原有设置的虚拟内存c盘(系统盘)为4096-8192。在我将虚拟内存改成1024-2048之后,然后tm报错了。就是上面的的这个错误:RuntimeError: Unable to find a valid cuDNN algorithm to run convolution。但是实际上,错误和cuda没有直接关系,目前我还不太清楚为什么虚拟内存直接关系到了cuda的运行环境,或者说pytorch的运行环境。网上搜了一下也没找到相关的资料,主要应该是我的理解太浅显。
网上关于yolov5 gpu环境搭建的文章也是一抓一大把,但是实际上好用不好用并不清楚。所以要想按照那些所谓的教程安装配置,很可能会失败。当然按照我的文章进行安装配置也可能会失败。逼乎上有个帖子问新手学习一门语言该不该用ide,还有一大群人建议新手配置各种环境,用sb vim等编辑器,配置各种执行路径,各种源代码路径、库路径。这tm一个ide就解决的问题,非得折腾半天,这是为了让没入门的赶紧放弃?
我简单的说一下我的安装流程:
1.下载cuda安装文件,https://developer.nvidia.com/cuda-downloads?target_os=Windows&target_arch=x86_64&target_version=10&target_type=exe_network 安装cuda,默认一路next 即可。
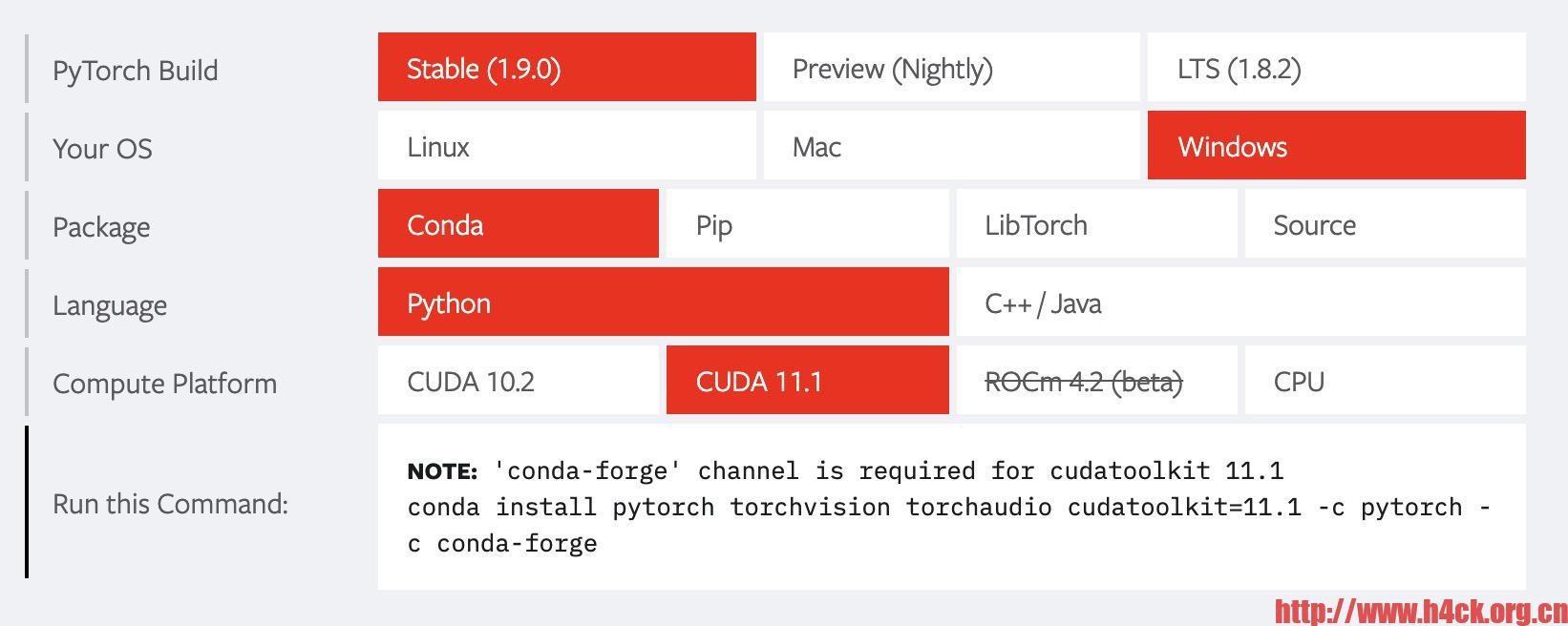
2.安装pytorch-gpu,yolov5的运行环境主要依赖于pytorch。通过官网https://pytorch.org可以找到对应的安装命令:
功能:支持全站爬取,搜索爬取。想下载什么内容自己定制,目前版本不支持独立页面下载,后续可能会考虑支持,目前我的目标是为了爬取整个网站,所以单页面下载功能不一定会做,即使做了也不一定什么时候会上。 参数说明:
xiurenji.exe 可执行文件名称 帮助: -h 显示帮助说明 必选参数: -a 整站爬取 -q 搜索爬取,针对关键字搜索之后对于搜索结果页进行爬取 可选参数: -p 制定下载目录,默认下载路径为当前exe所在目录下的images文件夹
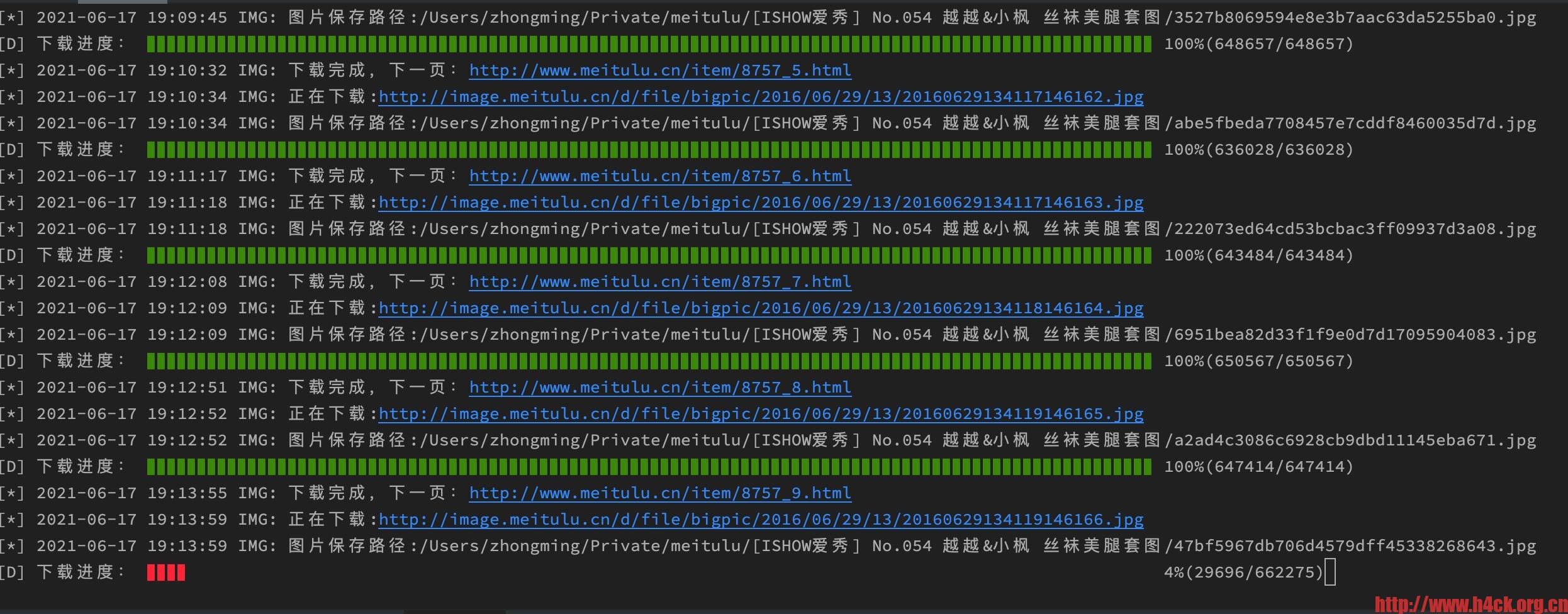
代码:
def proxy_get_content_stream(url):
if is_use_proxy:
socks.set_default_proxy(socks.SOCKS5, PROXY_HOST, PROXY_PORT)
socket.socket = socks.socksocket
return requests.get(url, headers=HEADERS, stream=True, timeout=300)
def save_image_from_url_with_progress(url, cnt):
with closing(proxy_get_content_stream(url)) as response:
chunk_size = 1024 # 单次请求最大值
content_size = int(response.headers['content-length']) # 内容体总大小
data_count = 0
with open(cnt, "wb") as file:
for data in response.iter_content(chunk_size=chunk_size):
file.write(data)
data_count = data_count + len(data)
now_position = (data_count / content_size) * 100
print("\r[D] 下载进度: %s %d%%(%d/%d)" % (int(now_position) * '▊' + (100 - int(now_position)) * ' ',
now_position,
data_count,
content_size,), end=" ")
print('')